Risk analytics is full of data engineering complexities. If you are modeling portfolios or accounts, managing risk exposures and concentrations, underwriting in the insurance or reinsurance side of a transaction, or broking risk, among the many challenges, you are often working with multiple exposure formats.
Each format will have its own encoding of exposures, contracts, and treaty terms, and typically there will be multiple versions of each format.
Sometimes this situation arises because you are utilizing models from various vendors, various vendor applications (such as Verisk/AIR models or applications like Touchstone, Sequel, Oasis Loss Modeling Framework (LMF) models, and so on) or you have received exposure files from your partners in data formats supported by these vendors.
The constant challenge of dealing with multiple data schemas, versions of these schemas, and trying to hit lossless data conversions and unification can be exhausting. Even a single translation error in one encoding between these formats can significantly impact the quality of your analytics.
All this can be greatly simplified. Moody’s RMS Intelligent Risk Platform™ addresses the complexity of exposure data schema mappings by allowing clients to import exposure data not only stored in the RMS Exposure Data Module (EDM) format but also in Verisk/AIR’s Catastrophe Exposure Database Exchange (CEDE) and soon the Oasis Open Exposure Data (OED) schemas, directly into the platform.
These new capabilities make it simple to bring all the exposure data into the platform and get a global view of a portfolio.
Clients no longer need to invest in developing, testing, and maintaining these complex schema mapping tools and deal with multiple versions of EDM, CEDE, and OED.
Verisk/AIR CEDE (Catastrophe Exposure Database Exchange)
The August 2023 Intelligent Risk Platform release introduces new services that enable users to import and transform exposure data stored in the CEDE v10.0 schema.
The service maps the exposure information (accounts, policies, locations, peril codes, Total Insured Value (TIV), occupancy codes, and construction codes), financial information (limits, deductibles, reinsurance, step policies, and special conditions), and secondary modifiers from CEDE to the IRP exposure and loss data format called the Risk Data Open Standard (RDOS).
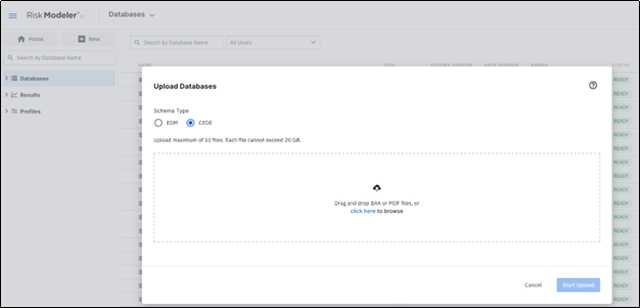
In the screenshot above, when users initiate the import process within the Risk Modeler™ application, they will be able to select the exposure schema in which the source data is stored.
To import exposure data stored in a CEDE schema, users simply select the ‘CEDE’ option, bring in up to ten files in an MDF or BAK format, select the sharing options, and initiate the import.
This workflow is very much like importing EDMs stored in MDF or BAK files. In addition, the same functionality of importing exposure data stored in the CEDE schema as MDF or BAK files is available through the APIs.
High-Fidelity Data Mapping
There are two important factors to consider with high-fidelity data conversion:
- The destination data type has to be able to represent multiple exposure data schemas and their representations. In the case of the Intelligent Risk Platform, we use the RDOS, a data type designed to be a superset of the EDM, CEDE, OED, and other data extensions that represent other lines of business besides ‘property.’ We will have more to say about the RDOS in the future.
- A high quality mapping service is required to preserve as much of the fidelity of the original data being ingested, whether that is an EDM, CEDE, OED, or something else. Let’s dig deeper into this aspect here.
The mapping services deployed in the IRP are designed to achieve high-fidelity mapping between the various exposure schemas.
This high level of fidelity is achieved through the development of mapping logic using a procedural programming language as opposed to a series of SQL scripts or procedures.
We know some attempts have been made to develop such mappings using SQL. This may seem straightforward, however, the overall fidelity of such mappings is very low.
Take peril mapping as an example. A CEDE schema uses ‘PerilSetCode’ to code perils/sub-perils in exposure.
The schema defines a set of peril and sub-peril codes and then creates all possible combinations and permutations of those codes, resulting in millions of possible values for the PerilSetCode field:
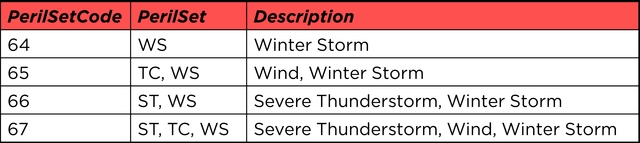
The platform defines the peril using seven possible values. The mapping engine needs to take millions of possible values from one side and map them to the seven values on the destination side.
Several clients have developed this mapping by defining the Moody’s RMS peril value for a much smaller set of CEDE PerilSetCode values that they frequently encounter.
Instead of defining and using a static lookup table, within the IRP, an algorithm is implemented to perform this peril mapping.
The algorithm considers the entire scope of the exposure (e.g. all PerilSetCodes present on a given location), decodes them by applying the PerilSet values, and then derives the set of Moody’s RMS peril values that would be the best representation of that exposure entity (e.g. location).
Another key aspect of high-fidelity mapping is the mapping of financial information, such as limits, deductibles, and TIVs. Different schemas store this information differently.
In the CEDE schema, TIV information is stored as columns (named ReplacementValue) whereas the EDM stores them as rows, where every row is a combination of peril and coverage.
The multi-step process of mapping such information includes identifying how many rows are required on the destination side, based on information present on the source side, and then populating each row with the appropriate values.
Lastly, the mapping of secondary modifiers between different schemas requires not only the mapping of the fields but also the values. Different schemas use different values for different secondary modifiers.
For example, the code for ‘Clay / Concrete Tiles’ is ‘3’ in CEDE but is represented with the value ‘5’ in EDM. As part of the development of the mapping engine, over a hundred secondary modifiers and their values were mapped between the CEDE and the EDM.
In its current state, the engine is using this pre-defined set of mappings and users do not have the ability to modify these mappings. In the future, the platform will provide a way for users to modify these mappings to fine-tune the mappings based on their exposures and needs.
Validation Report
In addition to the challenges of developing mappings between various schemas, clients face the additional challenge of validating those mappings. How do you verify that the mapping processed all the portfolios, accounts, and locations correctly?
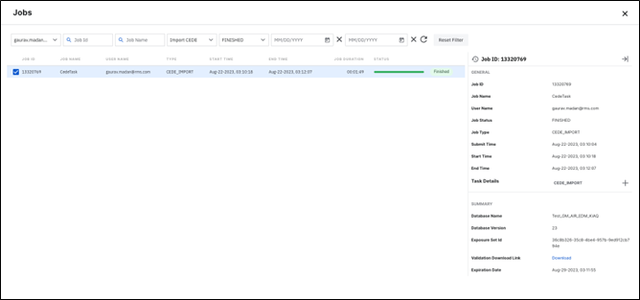
The Intelligent Risk Platform mapping service produces a validation report at the end of every successful job. Clients can access this report by going into the details of the mapping job and clicking the ‘download’ link.
The validation report is an Excel report with three worksheets: Counts, Distributions, and TIV.
The Counts worksheet provides a comparison of record counts between the imported CEDE database and the resulting EDM database.
This information allows users to get a high-level understanding of the records that the mapping engine processed. Any large difference in the count should warrant a deeper dive into the data to understand why those records were not mapped.
The Distributions worksheet, as the name suggests, provides side-by-side distributions by construction code, occupancy code, number of stories, and year built.
This information helps in validating the overall mapping but also provides insight into which Verisk/AIR codes were mapped to Moody’s RMS codes.
Lastly, the TIV worksheet contains the TIV breakdown by country and peril. Because the peril codes between CEDE and EDM do not align one-to-one and the fact that TIV is captured differently between the two schemas (rows versus columns), it is not possible to provide this detail as a side-by-side comparison.
However, this information is extremely valuable in confirming the mapping or identifying problem areas in case many accounts or locations were not mapped properly.
Oasis OED (Open Exposure Data)
While the capability of importing CEDE into the Intelligent Risk Platform is already available on the platform, Moody’s RMS is also developing the capability of importing exposure data stored in the OED schema into the platform.
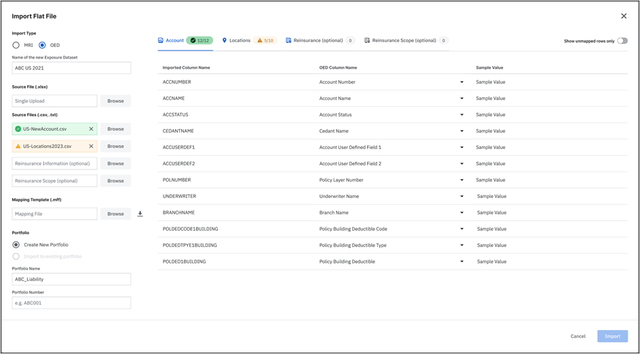
An OED schema consists of four files: Account, Location, Reinsurance, and Reinsurance Scope.
Because of this, the workflow for importing OED files is different than importing the CEDE databases. The OED import workflow aligns with the existing import workflow for MRI files and that is where users will get an option to select OED to import those files into the platform.
Why does this all matter? The simplification of dealing with data conversion can save a great deal of time in many different workflows.
Here are a few specific reasons why having a unified exposure store can be greatly helpful:
1. Global-View of Your Portfolios: If you are receiving exposure data from other parties in the value chain and often receive the data in various schemas, this can make it very difficult to get a global view of all portfolios.
With the import services available on the Intelligent Risk Platform, clients can import all exposures into the platform and get a global view. Also, clients who license the ExposureIQ™ application on the platform can perform portfolio management operations such as accumulations and analyze the global portfolio.
2. Blending Multiple Risk Views Next to Verisk/AIR Models: If you are looking to create your own view of risk by blending multiple modeling systems, the Intelligent Risk Platform and Risk Modeler can help.
Aside from using Touchstone, you can use the Intelligent Risk Platform import services to add Moody’s RMS models and, in the future, Oasis models to your risk view. (See details on the Moody's RMS and Nasdaq Partnership for Running Oasis Models here).
3. Migrating Away from Verisk/AIR Models: Clients selecting Verisk/AIR models may have a lot of data solely retained in the CEDE format.
Conversion can then help point this data toward Moody’s RMS and in the future, through the Open Modeling Engine at Oasis LMF models running on the Nasdaq Cat Modeling system.
For more information about this announcement and to participate in the preview program, clients can reach out to their Moody’s RMS representatives or email us at info@rms.com.








